
When you discourage search engines from indexing your WordPress site, it won’t be crawled, indexed and listed anywhere in search results. You’ve developed a website and optimized it to increase the chances of ranking in search results. So why do you want to block web crawlers and indexers?
By the end of the post, you’ll learn the 5 most important reasons to prevent your site from being indexed as well as solutions to disable the search engine indexing.
- Why Discourage Search Engines from Indexing Your WordPress Site
- Block Search Engines from Indexing WordPress sites
- 3 Common Myths about Robots.txt
- Stop Google from Indexing WordPress Pages and Posts
- Prevent Search Engines from Indexing WordPress Files
Why Discourage Search Engines from Indexing Your WordPress Site
There are 5 common cases you might want search engines to stop crawling and indexing your WordPress site and content:
1. Maintenance and coming soon pages
The maintenance page lets users know that your site is still under development. This page shouldn’t be indexed and appear in the search results because it won’t deliver any values once the site is live.
2. Duplicate content
You create a clone website for development purposes. However, you don’t want this site to compete with the existing one. It stands to reason that Google might treat them as duplicate websites and will list one out of these two in search results. What if it ranks your test site instead of the main one? Keeping the duplicate site away from Google proves useful to higher rankings of the more important website.
3. Valuable content
Visitors can search for order and thank-you page URLs, which include valuable offers, to steal your products. If that is the case, these pages shouldn’t be indexed and shown in search results publicly.
4. Personal content
When you write journals or diaries and post them on your blog website, you have a good reason to make it unsearchable. As a result, nobody will even know your blog’s existence.
5. Project management
While your team is working on a project, you can create a non-indexed site to share internal information with team members. This website will be hidden from Google’s crawlers. Only team members are able to search for and access the site.
Now we’ll show you particular solutions to disable search indexing, depending on the site areas you intend to protect.
Block Search Engines from Indexing WordPress Sites
There are 3 common options for you to block search engines from indexing WordPress sites:
- Password protecting a directory using cPanel
- Using a plugin to password protect the entire site
- Enabling WordPress Search Engine Visibility feature
Before digging into WordPress built-in feature, let’s get started with the password protection method. You can either provide a password for your site’s control panel tool or set a password through a plugin. Each method secures your website in a different way.
1. Password protect websites using cPanel
cPanel offers one of the most popular and convenient web hosting tools to manage all websites. In order to password protect your site, follow these 5 steps:
- Log into your cPanel dashboard and open Password Protect Directories
- Select the directory where your WordPress site is hosted on
- Choose Password Protect This Directory option
- Create a user account with a username and a password
- Save your changes
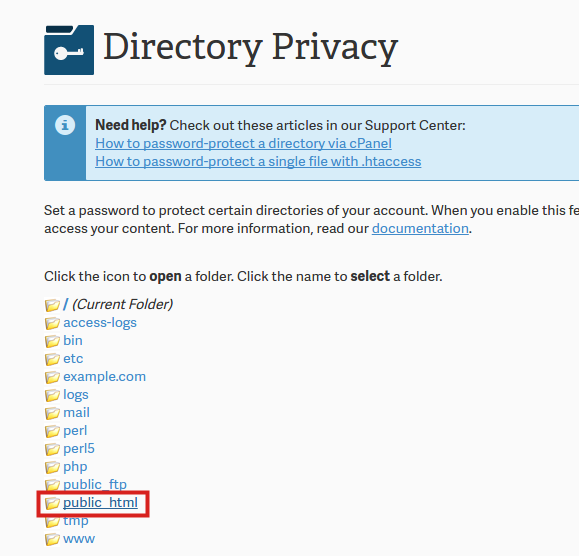
If the website is password protected through cPanel, users have to enter both username and password when accessing the website. That’s why you may consider using a password protection plugin.
2. Use Password Protect WordPress (PPWP) Pro plugin
Password Protect WordPress Pro protects your WordPress site with a single password while keeping it away from web crawlers and indexers. This method gives you more control over the cPanel’s password protected directories tool as it doesn’t require a username.
Upon activation, you need to:
- Head to the Settings page
- Make sure the Block Search Indexing advanced feature is enabled
- Go to Entire site tab and enter a password to protect your site
- Save your changes

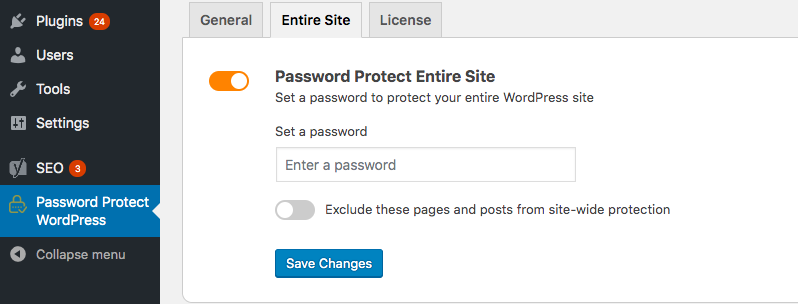
Once password protected, your website becomes invisible to web crawlers and won’t be shown anywhere in search results. Only those with the correct passwords can unlock the private site.
On top of that, the plugin enables you to exclude some pages from the site-wide protection. In other words, these pages will be searchable while the rest of the website is hidden from search engines.
3. Use WordPress Search Engine Visibility feature
WordPress provides a built-in option to discourage search engines from indexing your website. To enable the option, you should:
- Find Settings in WordPress dashboard
- Click on Reading option underneath
- Enable “Discourage search engines from indexing this site” option
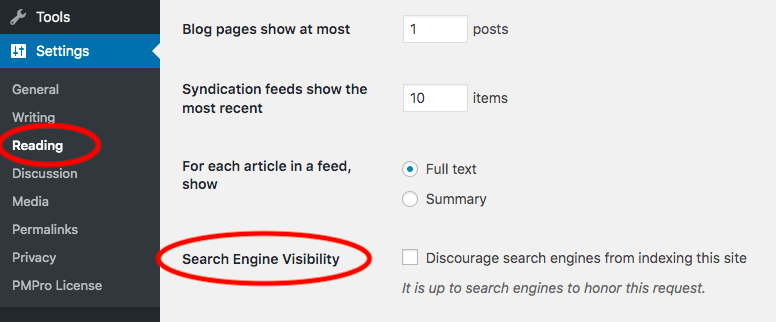
As soon as you click on the Discourage search engines from indexing this site checkbox, WordPress uses robots.txt file and meta tag to shield your site from the web crawlers and indexers.
WordPress edits robots.txt file by using the following syntax:
User-agent: * Disallow: /
At the same time, it adds this line to your website header:
<meta name='robots' content='noindex,follow'/>
You may wonder if this is a good solution to discourage search engines from indexing your site. It affects your site’s SEO ranking. It’s hard for your content to pick up the ranking.
3 Common Myths about Robots.txt
Robots.txt is a text file webmasters created to instruct search engines not to crawl pages on your website. Many people, including WordPress, recommend using it to restrain the websites, content, and files indexing.
However, not all of us know how to use robots.txt files properly. Below are 3 common myths about robots.txt that most users misunderstand.

1. Robots.txt helps block search indexing
WordPress site owners believe that robots.txt disallow rules come into common use to prevent search engines from indexing your site. However, it’s not meant to block search indexers but to manage the crawling traffic to your site. For instance, you use robots.txt to avoid crawling unimportant or similar pages. What’s more, you can use robots.txt when there are a lot of requests from Google’s crawlers to your server.
To block search engines from indexing your site, you should consider using robots meta tag and x-robots-tag HTTP header.
2. Content won’t be indexed without being crawled
Google follows 3 basic steps to generate results from web pages, namely crawling, indexing, and serving.
- Firstly, crawling is when Google discovers all pages existing on your website. It uses many techniques to find a page, such as reading sitemaps or following links from other sites and pages.
- Next, Google indexes your pages by analyzing and understanding what the page is about. This information will be stored in a huge database called Google index.
- Lastly, Google starts ranking your content. Whenever someone enters a keyword in the search bar, Google will find and serve the results with the most relevant content from its index. These results will be based on over 200 factors, including the page content quality, user’s location, language, and device, etc.
So you might think that if your content isn’t crawled, it won’t be indexed. As robots.txt file blocks Google crawlers, it will prevent search indexing as well?
In point of fact, pages blocked by robots.txt won’t be crawled but will still be indexed when they’re linked from other websites. Chances are your pages still appear in the search results.
3. Robots.txt is used for hiding content
People often use robots.txt file to prevent content from appearing in search results. However, robots.txt tells Google not to read, analyze, and understand the content. So search engines won’t know whether they should index your pages or not. As a result, Google doesn’t provide a meta description for the page. Instead, users will see a line telling “No information available for this page. Learn why”.

Robots.txt is NOT used to hide content. In fact, robots.txt makes it harder for Google to analyze and shield your private content. To effectively hide the content, you must use other methods such as password protection or “noindex” meta tag.
As mentioned, WordPress Search Engine Visibility feature works based on robots.txt file. That’s why it doesn’t perfectly discourage search engines from indexing your content.
Limitations of robots.txt
There are some limitations you should take into account when using robots.txt.
1. Robots.txt file is publicly available
Robots.txt file is accessible to anyone. As a matter of fact, robots.txt files of all sites are located at the root domain and /robots.txt, e.g. www.example.com/robots.txt. When putting the URLs of pages and files in the robots.txt file, you accidentally invite unintended access. Bots & users will know which pages should be hidden. Then, they are able to get the URLs and access these pages easily
To overcome that drawback, you need to group all the files you want to disable search indexing in a separate folder. Then, put your files in that folder and make it unlisted on the web. After that, list only the folder name in /robots.txt.
2. Other search engine robots can ignore your robots.txt file
Although most robots follow your robots.txt, malware and email address harvesters used by spammers can ignore it. These bad robots might visit and scan your site for information such as emails and forms to send spam emails.
You should use firewalls, IP blockers, and security plugins to enhance the security of your WordPress site.
3. Each search engine crawler might read the syntax differently
The syntax in a robots.txt file is applied for most web crawlers. Still, each of them can read and follow the file’s rules in a different way. That explains why some crawlers don’t follow the file disallow rules and continue to crawl your site.
You shouldn’t depend too much on robots.txt to manage the crawling traffic.
The importance of robots.txt
Robots.txt file turns out to be useful when you clearly understand how it works. It doesn’t hinder the content from being indexed. Robots.txt file is used to manage the crawling traffic and prevent the uploads from showing up in Google search results. This feature will be discussed in the Prevent Search Engines from Indexing Files section below.
Stop Google from Indexing WordPress Pages and Posts
Instead of keeping the entire site away from crawlers and indexers, you might intend to deindex some specific pages only, such as pages with confidential information or thank-you pages.
In order to prevent Google from indexing your content, take one out of these 3 separate paths: editing the robots meta tag, using X-Robots-Tag HTTP header, or using Protect WordPress Pages and Posts plugin.
1. Use robots meta tag
Adding the noindex meta tag to (X)HTML pages prevents Google from indexing and making your content available in search results.
Place the robots meta tag in the <head> section of the chosen page, for example:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
The value “robots” after the meta name identifies that the page or post applies to all crawlers. Replace “robots” with the name of a specific bot you intend to block its indexing, e.g Googlebot – a Google’s crawler. Visitors won’t be able to find your content in Google search results, but via other search engines like Bing or Ask.com.
What’s more, it’s possible for you to use multiple robots meta tags at the same time, in case you want to specify different crawlers individually. For example:
<meta name="googlebot" content="noindex"> <meta name="googlebot-news" content="nosnippet">
2. Use x-robots-tag HTTP header
Similar to the robots meta tag, you can also use the X-Robots-Tag HTTP header to stop search engines from indexing your page-level content. Place the following syntax to your HTTP header:
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT (…) X-Robots-Tag: noindex (…)
Robots meta tag and x-robots-tag HTTP header methods seem too complicated for those don’t have good coding skills. Fortunately, Protect WordPress Pages and Posts simplifies the way you use robots meta tag and x-robots-tag HTTP header.
3. Use Protect WordPress Pages and Posts Plugin
Protect WordPress Pages and Posts hides your content from indexers bases on the way robots meta tag and x-robots-tag HTTP header work.
Users can’t find your original content URLs. Instead, the plugin auto-generates unique private links that allow you to share protected pages and posts with others. You’re able to customize these links to make them meaningful, memorable and legitimate as well.
To keep the content out of being widely shared with others, you can expire the private links within a number of days or clicks. For example, you can set the link usage to one time. Users will see a 404 page after every page load.
Prevent Search Engines from Indexing WordPress Files
There are a number of techniques to make your files invisible to web crawlers, such as editing robots.txt files, protecting attachment pages, or using Prevent Direct Access plugin.
1. Edit robots.txt
As mentioned above, robots.txt file doesn’t prevent search engines from indexing your individual web pages. It only keeps media files, except PDFs and HTML, away from Google’s eyes. Place the following syntax to the given file you wish search engines to exclude:
User-agent: Googlebot-Image Disallow: /[slug]/
Update the slug with the specific file URLs you would like to block search indexing. You can also add the dollar ($) symbol to block all files ending with a specific URL string. For example:
User-agent: Googlebot Disallow: /*.xls$
All files ending with .xls is blocked from Google indexing now.
2. Stop Google from indexing attachment pages
Another method to stop search engines from indexing files is through attachment pages.
Attachments refer to any types of website uploads, such as images, videos, and audios. As soon as a file is uploaded, WordPress creates an attachment page that includes the file as well as relevant captions and descriptions.
You should stop search engines from finding and ranking these pages as they contain very little to no content. These pages might disappoint visitors who desire to search for informative articles.
There are various ways that make Google unable to index your WordPress attachment pages, either manually editing the robots meta tag and x-robots-tag HTTP header or using the Yoast SEO plugin.
Editing robots meta tag and x-robots-tag HTTP header for attachment pages follows the same process as editing meta tag and x-robots-tag HTTP header for standard pages. However, this method seems too difficult and time-consuming if you want to prevent multiple files from being indexed at the same time.
3. Use Yoast SEO plugin
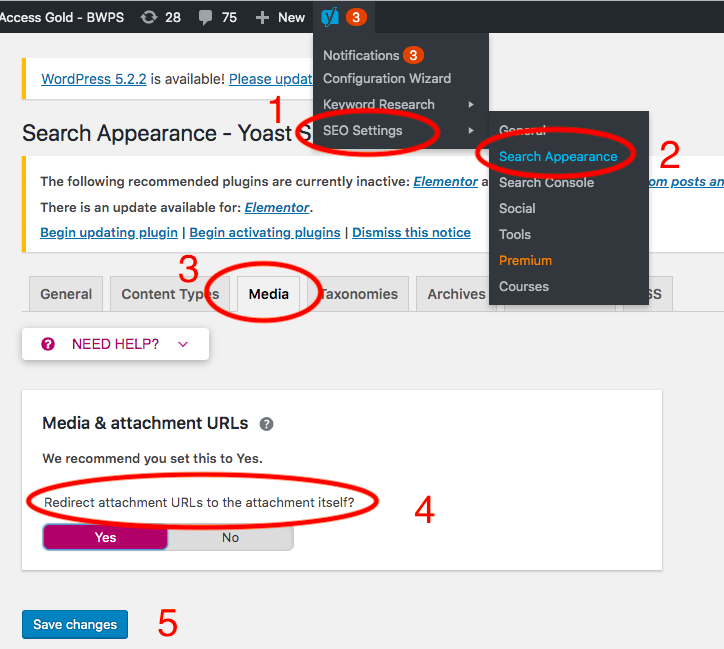
You can also use Yoast SEO to keep your files away from Google’s crawlers and indexers. Activate the plugin and follow these 5 steps:
- Go to SEO Settings in the Yoast dropdown
- Choose Search Appearance
- Head to Media tab
- Enable “Redirect attachment URLs to the attachment itself” option
- Save your changes
4. Use Prevent Direct Access Gold plugin
Prevent Direct Access Gold blocks search engines from indexing your files. Unlike robots meta tags and x-robots-tag HTTP headers, the plugin doesn’t require any technical coding.
Once activated, the plugin will automatically place a “noindex” meta tag on the <head> of every attachment page to disable search indexing.
<meta name="robots" content="noindex">
You can refer to this tutorial video for a more visual guide.
Ready to Block Search Engine from Indexing Your Site?
It’s not easy to manually block search engines from indexing WordPress sites, content, and files. You need to look for solutions to simplify the process.
You can install Password Protect WordPress Pro to keep your entire site away from the web crawlers. It’s because the Reading built-in feature still allows crawlers to go in and index your site if it’s linked from other sites and pages.
Find editing meta tag and X-Robots-Tag HTTP header too complicated? Protect WordPress Pages and Posts plugin automatically keeps pages and posts invisible to search engines with ease.
Prevent Direct Access Gold plugin saves you a lot of time to disable search engines from indexing WordPress files and attachment pages. It’s quicker than blocking individual files with robots meta tag or X-Robots-Tag HTTP header.
Please leave a comment below if you have any questions on how to prevent your WordPress site from being crawled and indexed.
